
Building-Scale Robot Navigation via a Relay of External Cameras
- Daniele De Martini
- Deployment , Site driven robotics
- May 22, 2026
Most robotic navigation systems rely on a familiar stack: onboard sensors, carefully calibrated cameras, detailed maps, and expensive localisation pipelines.
We wanted to explore the opposite direction: what happens if the robot itself becomes extremely simple, and the intelligence moves into the environment instead?
This work builds on our earlier research on calibration-free visual servoing from a single remote camera. In that setting, we showed that a robot could be robustly controlled entirely in image space without requiring calibrated geometry or onboard sensing. The natural next question was whether the same idea could scale beyond a single viewpoint. Could multiple uncalibrated cameras cooperate to control a robot across an entire building?
In our recent work,we built a system that enables a mobile robot to autonomously navigate an entire office floor using only wall-mounted cameras, without requiring camera calibration, pre-measured camera poses, SLAM, or even onboard sensing. Instead, the robot is controlled entirely from remote viewpoints distributed throughout the building.
The result is a form of building-scale visual servoing: a robot that can move through multiple rooms and corridors by being continuously handed over between overlapping cameras.
This post provides a high-level overview of the system and its ideas. Full technical details are available in the paper.
Moving Intelligence Into the Environment
Modern mobile robots are usually self-contained systems. They carry their own sensors, compute, localisation stack, and safety systems onboard. That works well for individual robots, but scaling quickly becomes expensive and operationally complex.
An alternative is to move sensing and computation into the environment itself: if a building already contains cameras and network infrastructure, why should every robot need its own perception stack?
The challenge is that more traditional camera-based visual-servoing control depends on careful calibration. Cameras must know where they are, how they relate to one another, and how image coordinates map into the world. Installing and maintaining these systems is often slow and brittle.
We wanted to eliminate that requirement entirely.
A Relay Network of Cameras
Our system treats each camera as an independent control node: each viewpoint detects the robot, estimates its orientation, plans paths directly in image space, and locally controls the platform. As the robot moves through the environment, control is handed off between overlapping cameras — like a relay race.
Crucially, the cameras do not share a global coordinate frame. The system has no knowledge of camera poses, building geometry, or inter-camera calibration. Instead of constructing a metric map of the environment, the system builds a topological representation of connectivity between viewpoints.
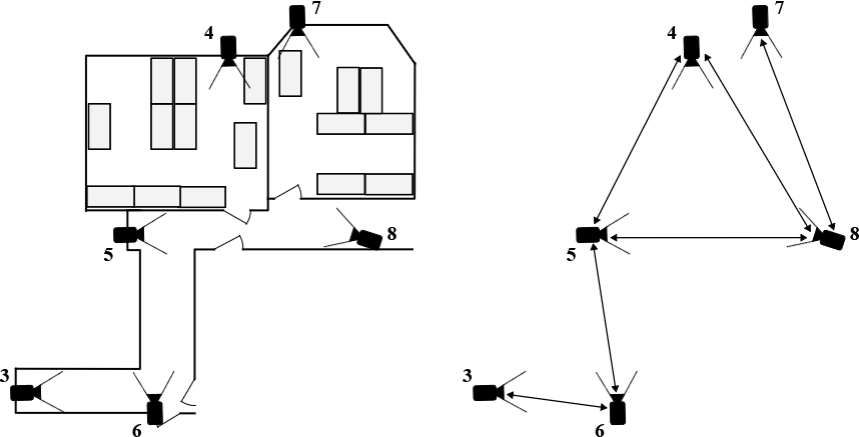 Fig 1: The floor of the Oxford Robotics Institute has been “sensorised” with CCTV cameras, which cover the whole space. Each camera does not know about the absolute position of the other cameras, but only how to reach the neighbouring ones.
Fig 1: The floor of the Oxford Robotics Institute has been “sensorised” with CCTV cameras, which cover the whole space. Each camera does not know about the absolute position of the other cameras, but only how to reach the neighbouring ones.
Each camera becomes a node in a graph, while overlap regions between cameras become edges that allow the robot to transition from one viewpoint to another. This dramatically simplifies deployment in real environments where precise calibration is impractical or costly to maintain.
Learning Connectivity by Watching People
One of the most interesting aspects of the system is how the camera network configures itself: rather than manually defining overlap regions, the system discovers them automatically by observing people as they naturally move through the workspace.
When the same person appears in two camera views simultaneously, a person re-identification model matches them across viewpoints. Repeated observations allow the system to infer which image regions correspond to the same physical location. Over time, these observations form stable handover regions between cameras and incrementally construct a graph of the environment.
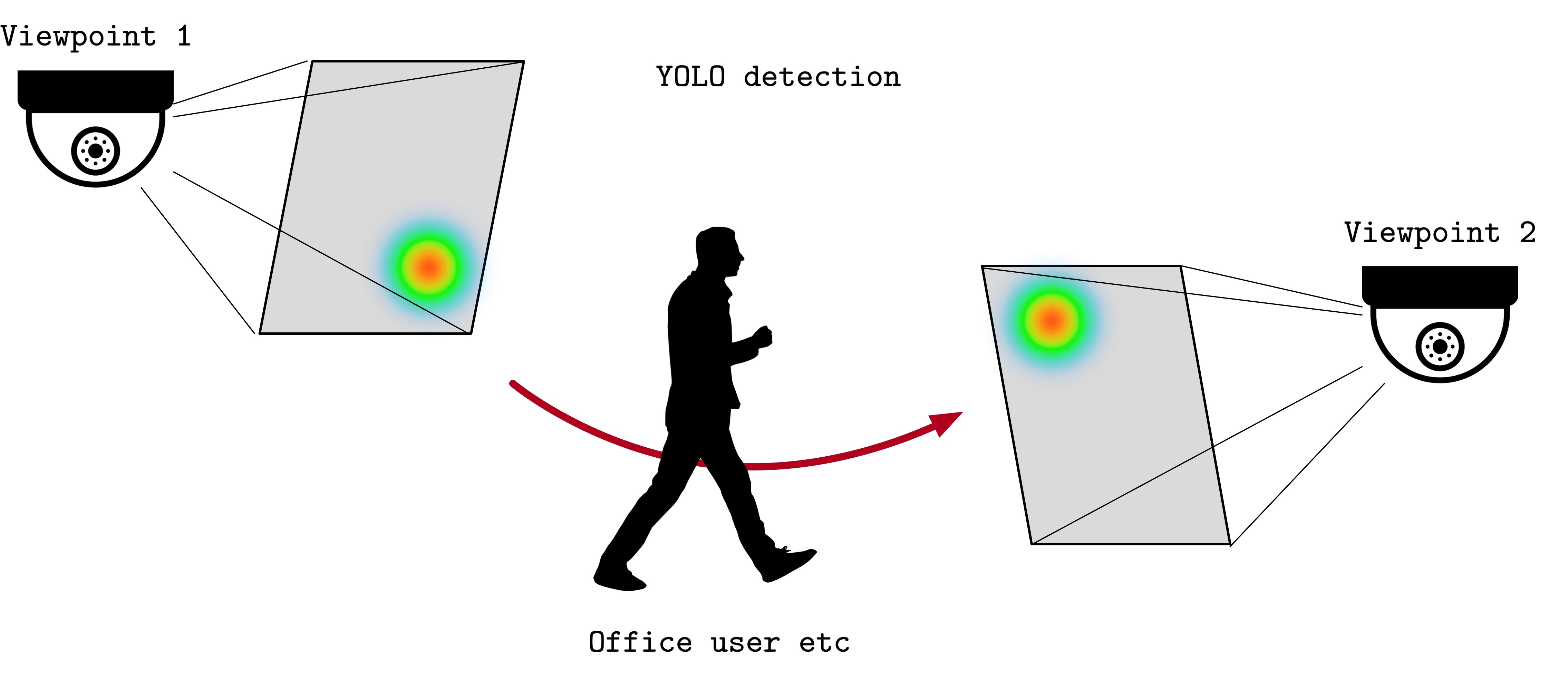 Fig 2: While people naturally move in the environment, our system detects them and understands if the same person is visible simultaneously in two cameras, thus creating a topological edge between them.
Fig 2: While people naturally move in the environment, our system detects them and understands if the same person is visible simultaneously in two cameras, thus creating a topological edge between them.
No calibration targets are required. No robot exploration procedure is required. The network simply learns from normal human activity inside the building. This makes the system naturally extensible: new cameras can be added to the network and incorporated through continued observation.
Planning Directly in Image Space
Once the camera graph exists, navigation becomes hierarchical. At the high level, the system decides which sequence of cameras the robot should traverse. At the low level, each camera independently plans and controls motion within its own image.
Path planning is performed directly in image coordinates using a Hybrid A* planner, while control uses a pure-pursuit controller adapted for perspective-distorted views.
Because the system never reconstructs a shared world model, it avoids many of the complexities associated with traditional multi-camera localisation systems.
Deployment in a Real Office Environment
We evaluated the system in a real office environment consisting of multiple rooms, narrow corridors, cluttered workspaces, and six overlapping cameras.
The robot autonomously traversed the environment for roughly forty minutes continuously while being handed off between viewpoints.
Fig 3: The robot reliably traverses the environment, relying solely on external sensing and computation. At each handover point, the next camera takes ownership of the control of the robot and drives it towards the goal, or the next camera.
We also compared the system against both human teleoperation and a traditional SLAM pipeline. Despite operating entirely from remote cameras, the system remained surprisingly competitive. Autonomous traversal times were only modestly slower than direct human control while avoiding several localisation failures encountered by the SLAM baseline in visually repetitive corridors.
One particularly interesting observation was that static environmental cameras avoided a common failure mode of onboard localisation systems. Since the cameras only need to detect the robot itself — rather than estimate global position from sparse environmental structure — long featureless spaces became far less problematic.
Why This Matters
This work is part of a broader shift toward environment-embedded robotics.
Instead of making every robot increasingly complex, intelligence can be distributed across shared infrastructure: cameras, edge compute, and learned environmental representations.
For controlled indoor environments such as offices, warehouses, hospitals, and industrial sites, this tradeoff becomes compelling. Robots become cheaper and simpler, while sensing and computation can scale independently from the fleet itself.
More broadly, we believe systems like this point toward a different model of robotics infrastructure — one where buildings themselves become part of the autonomy stack.
Limitations and Future Work
The current system still has important limitations.
The approach depends on sufficient camera overlap, reliable robot visibility, and largely static environments. Dynamic obstacles remain an open challenge, and crowded scenes can make person re-identification more difficult when constructing the camera graph.
Performance also depends heavily on camera placement. Poorly positioned viewpoints can reduce controllability or create weak handover regions between cameras. And it works with only a single robot… for now.